
Notice
Recent Posts
Recent Comments
Link
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 | 31 |
Tags
- NLB
- SAA-C03
- FTP
- Ebs
- AWS 자격증
- vyos
- AWS
- NAT
- aws SAA-c03
- Kubernetes
- tftp
- 3 TIER
- docker
- aws cloud school
- Troubleshooting
- IAM
- ALB
- aws cloud school 8
- GNS3
- DNS
- aws cloud shcool 8
- Firewall
- eks
- aws cloud
- EC2 인스턴스
- linux
- vmware
- 네트워크
- EC2
- aws saa
Archives
- Today
- Total
나의 공부기록
[AWS] 04-1. 시작 템플릿 & Auto Scaling 본문

시작 템플릿
- Auto Scaling의 Scale In/Out을 위해 시작 템플릿을 배움
- 이미지에는 인스턴스 유형이나 보안그룹 같은 설정이 포함되어 있지 않음
➡️ Auto Scaling을 통해 서버가 생성될 때마다 보안그룹을 일일이 지정을 하는 게 현실적으로 불가능
👉 이미지와 '인스턴스를 생성할 때 설정했던 내용들'(네트워크 설정 등...)을 미리 정의하기 위한 목적
시작 템플릿 구성 과정

더보기

내부 부하테스트

AMI 이미지를 만들었을 때, 서비스를 잘 제공하는지 확인



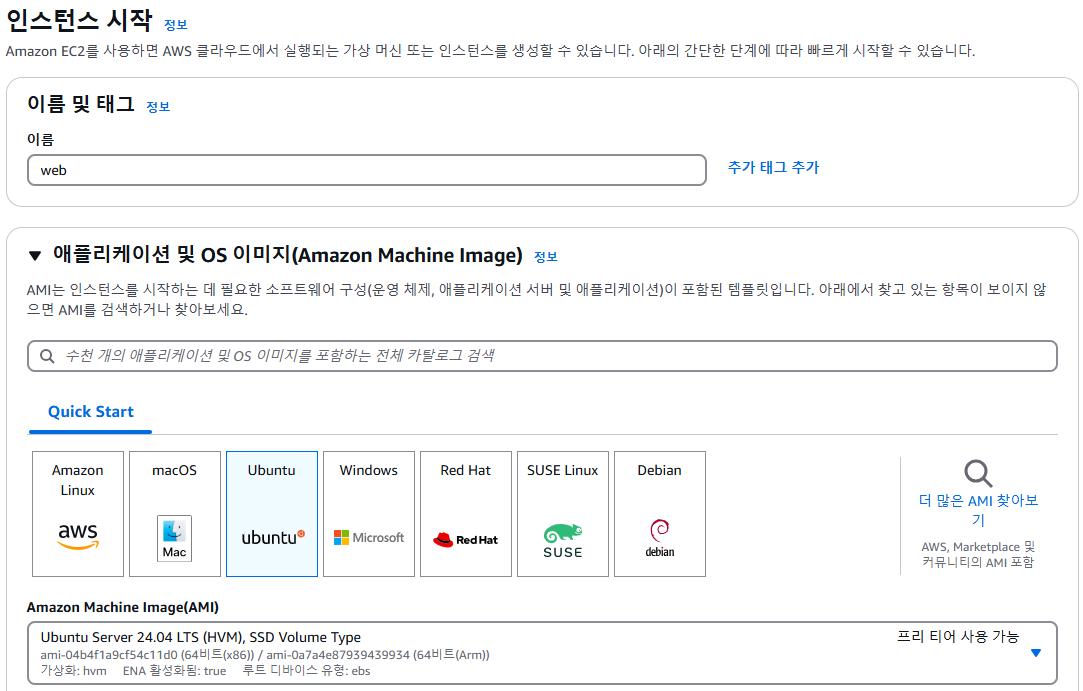
1. web 인스턴스 생성
2. web 설정
- 관리자 권한 부여 & apt 업데이트
ubuntu@ip-10-10-1-225:~$ sudo -i
root@ip-10-10-1-225:~# apt update -y- nginx 설치
root@ip-10-10-1-225:~# apt install -y nginx- index.html 파일 생성 & 서비스 확인
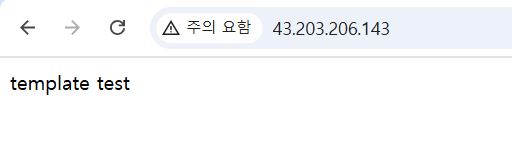
root@ip-10-10-1-225:~# echo 'template test' > /var/www/html/index.html
root@ip-10-10-1-225:~# curl localhost
template test- 재부팅 시, 서비스 유지 설정
root@ip-10-10-1-225:~# systemctl enable nginx
Synchronizing state of nginx.service with SysV service script with /usr/lib/systemd/systemd-sysv-install.
Executing: /usr/lib/systemd/systemd-sysv-install enable nginx
3. 부하 테스트 패키지 설치
- 외부에서의 부하테스트는 비용이 많이 청구되기 때문에, 내부에서 부하테스트 진행
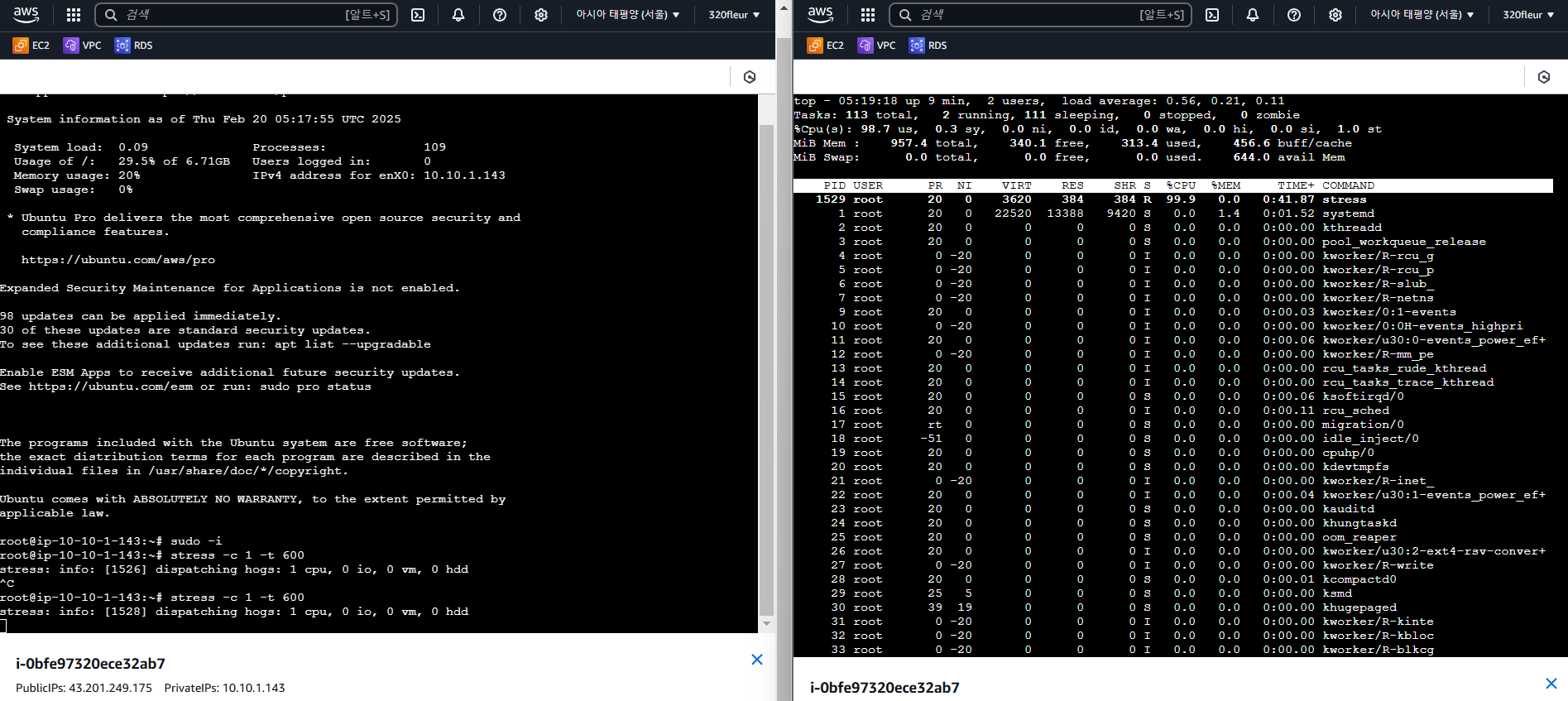
root@ip-10-10-1-225:~# apt install -y stress
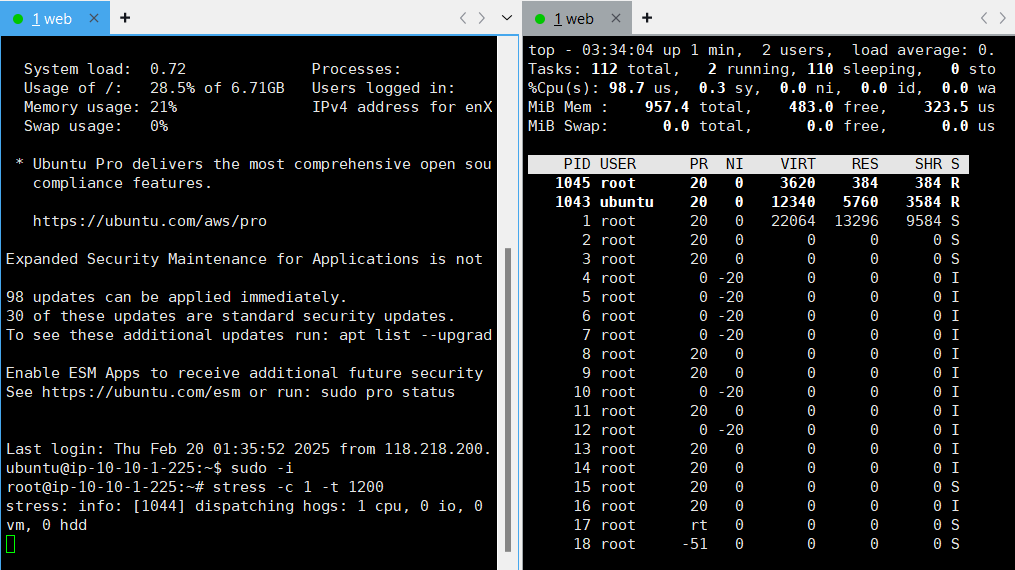
4. 부하 테스트 - CPU 사용량 확인
- CPU 1개에 대해 600초 동안 부하를 줄 것임
➡️ 10분동안 1 core에 대한 부하가 100% 발생
👉 추후에 Auto Scaling을 하면, CPU 사용량이 Scale In/Out의 지표가 되도록 설정하고 싶음
root@ip-10-10-1-225:~# stress -c 1 -t 600- web 인스턴스의 SSH 세션 생성 ➡️ CPU 사용량 확인
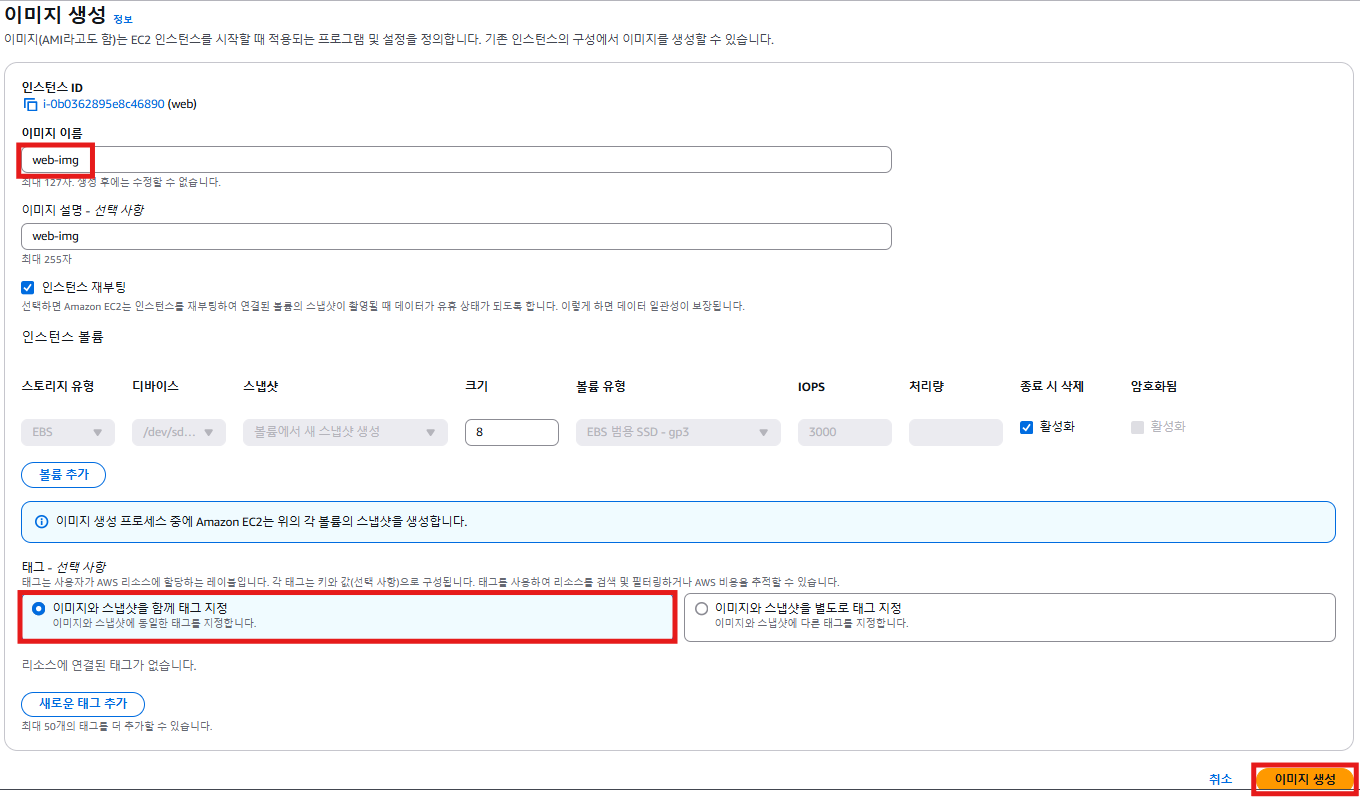
root@ip-10-10-1-225:~# top5. 이미지 생성
- 인스턴스 중지 & 재시작
- 이미지 생성 ➡️ 이미지 생성까지 시간이 소요됨
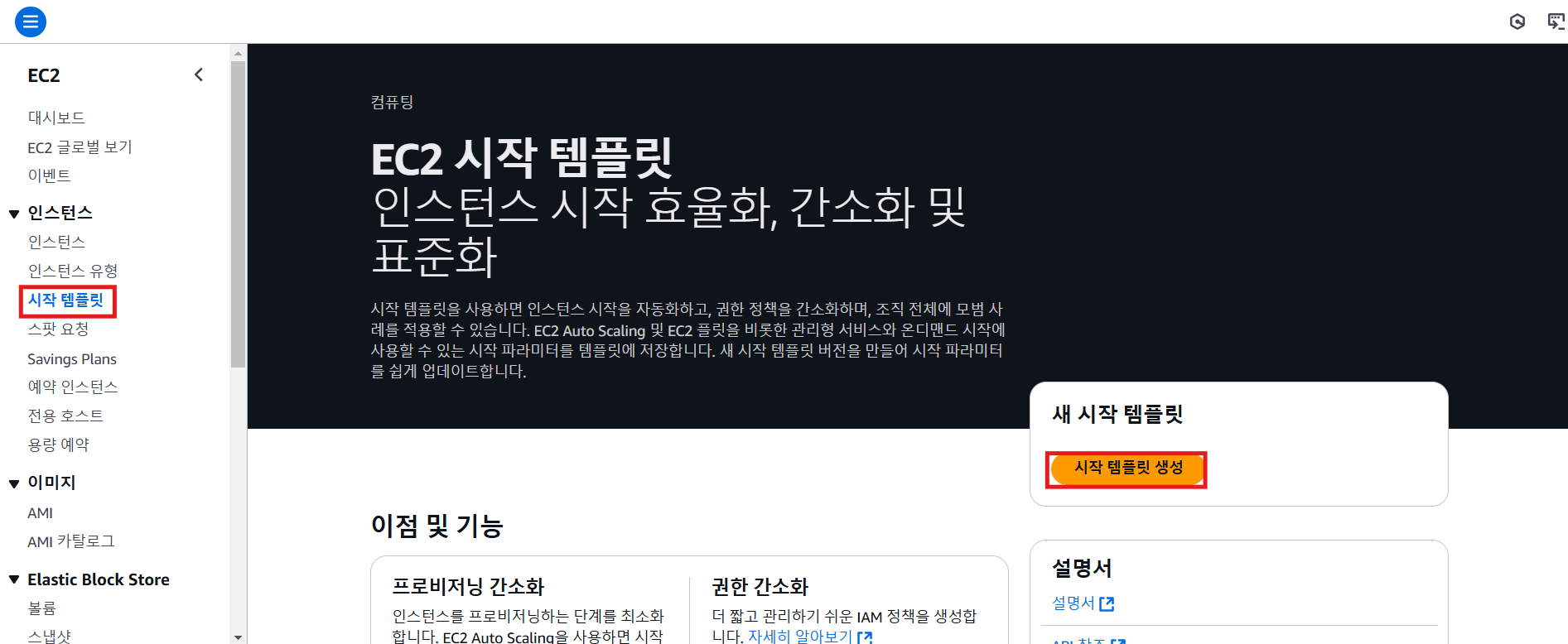
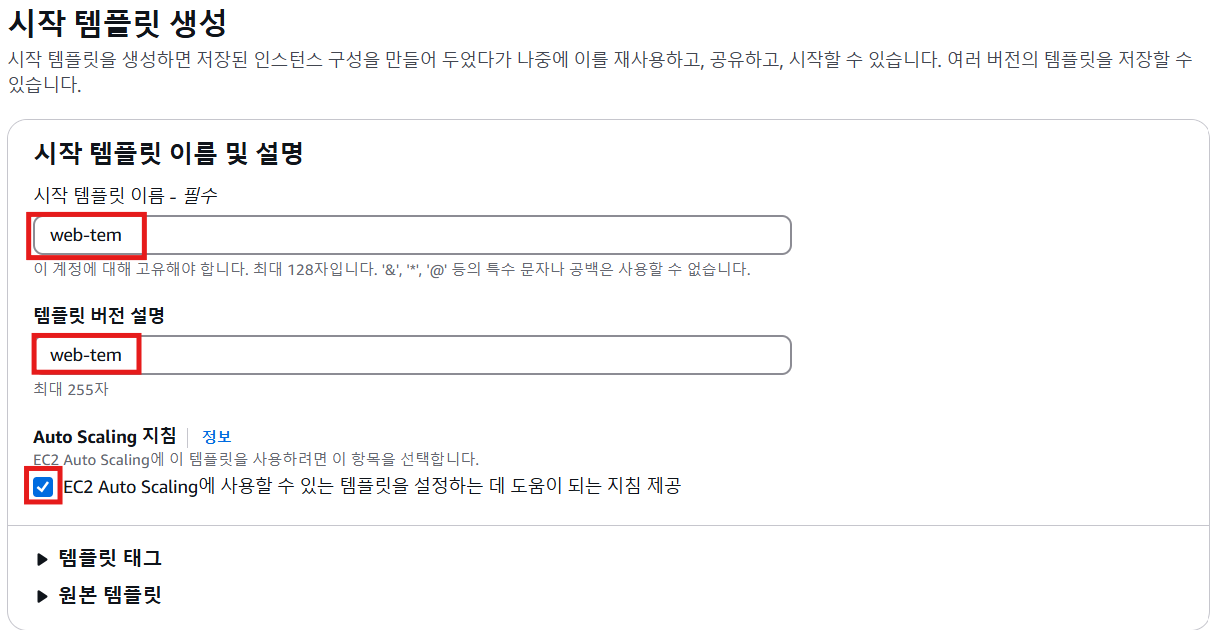
6. 시작 템플릿 생성
- 이미지가 다 생성된 후에 시작 템플릿 생성
- 보안그룹을 제외한 다른 네트워크 설정은 할 필요가 없음
➡️ 네트워크 설정(서브넷 등...)을 설정하면 특정 네트워크에서만 시작 템플릿이 생성됨
= 다양한 네트워크에서 사용하려면 네트워크 설정 ❌
- 기존의 시작 템플릿을 가지고 버전을 변경해서 수정할 수 있음
- Auto Scaling 지침을 선택하면, Auto Scaling에 대한 지침 제공
- AMI 이미지 선택
- 추후에 서버에 접근해서 stress(부하) 발생시켜야 하기 때문에, 키페어 필요
- 서브넷은 여러 개의 가용영역에 걸쳐서 시작 템플릿을 사용하고 싶기 때문에 선택하지 않음
➡️생성되는 서버들이 여러 서브넷에 고루 배치되도록 하고 싶기 때문에 - 방화벽은 기존에 존재하는 보안그룹 선택
- vpc마다 같은 보안그룹명이 존재하면 구분이 어렵기 때문에, 보안그룹 생성 시에 명칭을 구분하기 쉽게 작성해야 함
- 보안그룹은 vpc에 종속되기 때문에, 해당 vpc에 포함되는 보안그룹을 선택해야 함💡
Auto Scaling
- CPU, 메모리, 디스크, 네트워크 트래픽과 같은 시스템 자원들의 메트릭(Matric) 값을 모니터링하여 서버 사이즈를 자동으로 조절하는 서비스
- 가장 큰 목적 = 고가용성(High-Availaility)
Auto Scaling 종류
- Sacel Out ↔️ Scale In(서버의 개수가 줄어듦)
- 서버의 갯수가 늘어남
- Scale Up ↔️ Scale Down
- 서버의 리소스가 증가
- vcpu가 2 core ➡️ 4 core
- 주로 Scale In/Out 방식을 사용함
- 리소스를 수정하기가 어려움
- 임계점을 설정하고 임계(부하)를 인지해서 Scale에 변화를 줌
Auto Sacling 구성 순서
1) ELB & 빈 타겟그룹 생성 ➡️ 2) 빈 타겟그룹으로 로드밸런서 완성 ➡️ 3) Auto Scaling Group 생성 & 빈 타겟그룹에 넣어줌
더보기











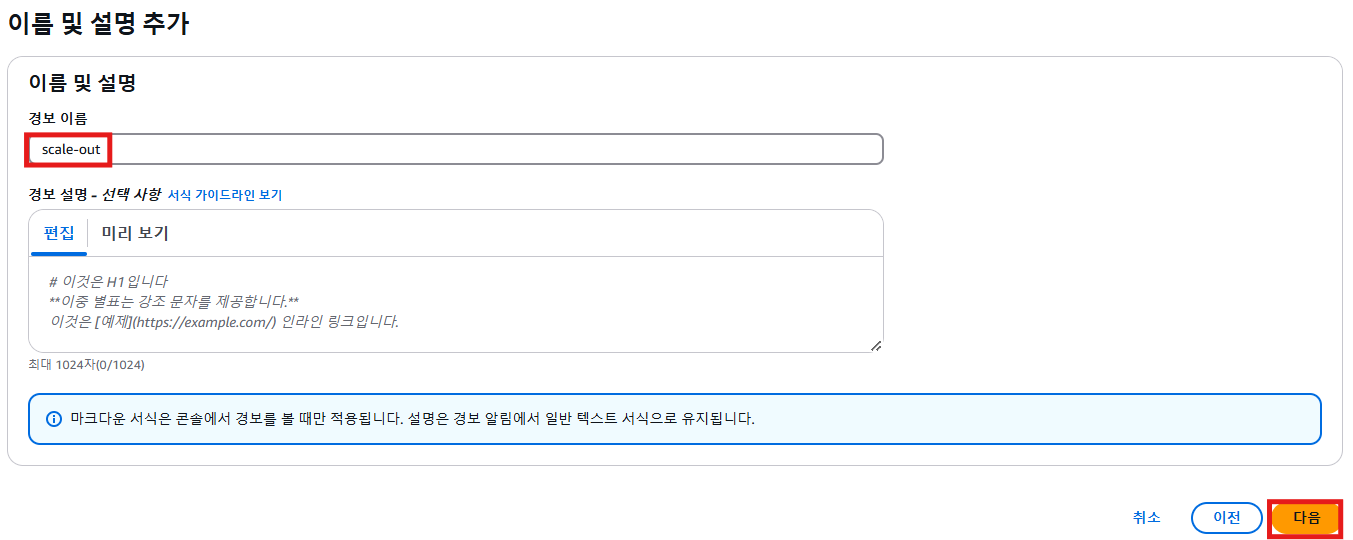
scale-out에 대한 정책











1. ELB 생성 - ALB
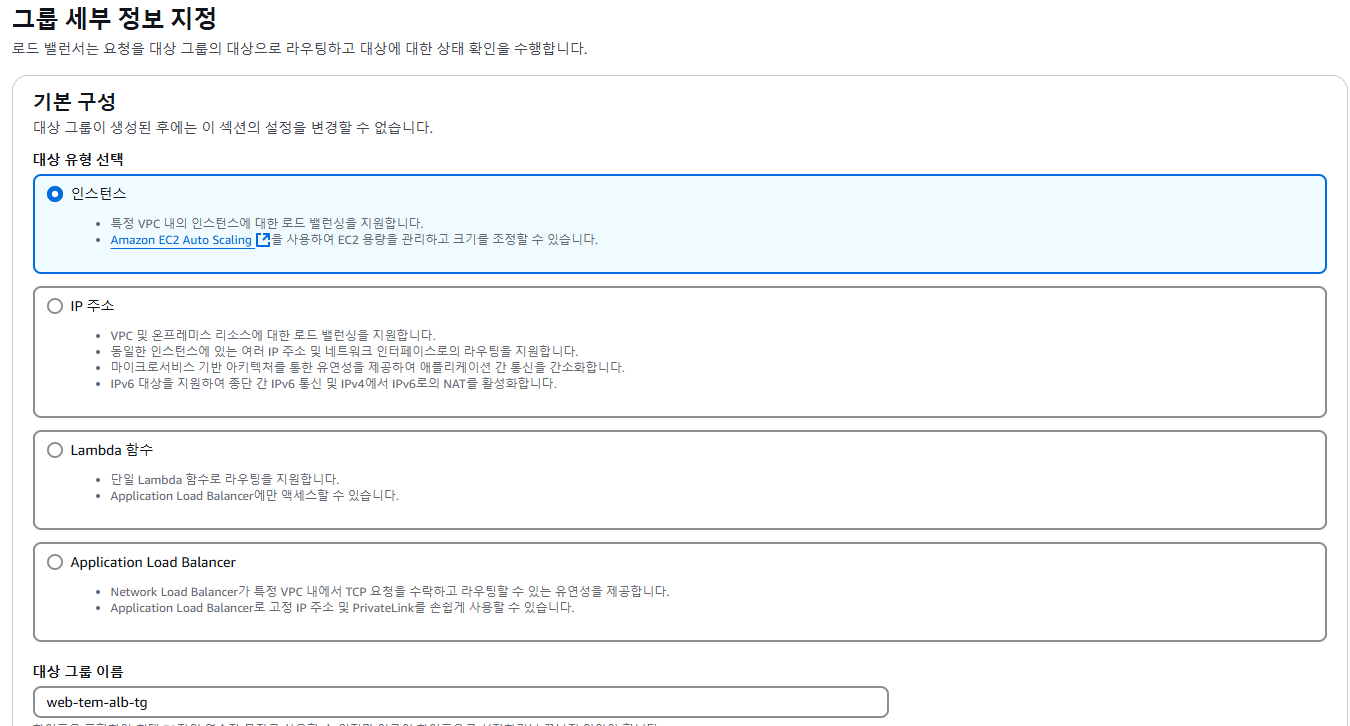
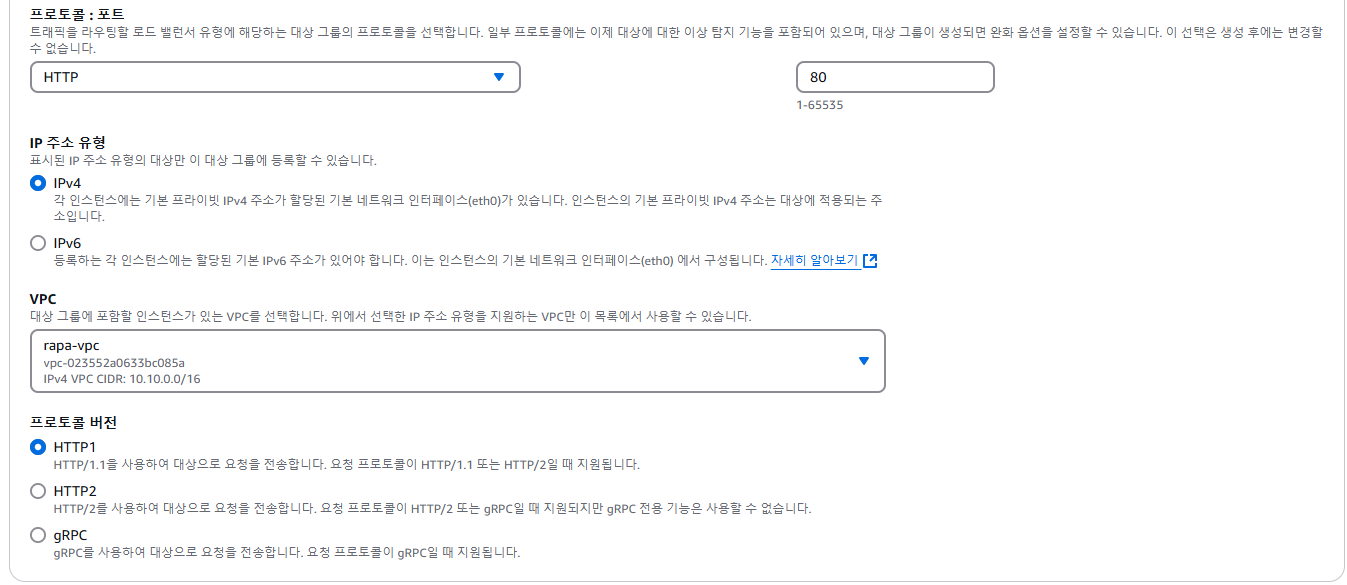
2. 빈 타겟그룹 생성
- 빈 대상그룹 생성
3. 빈 타겟그룹으로 로드밸런서를 완성
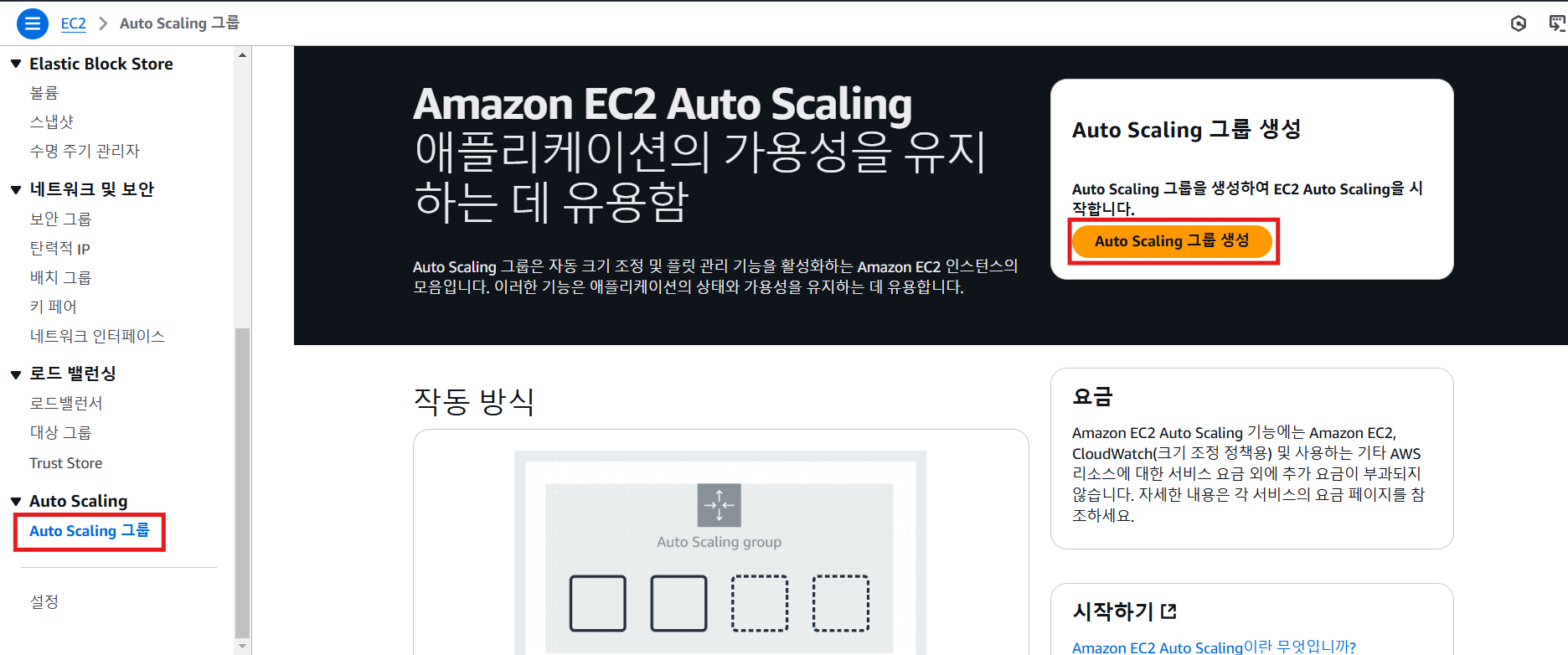
4. Auto Sacling Group 생성
- 인스턴스 시작 옵션 선택
- 다른 서비스와 통합
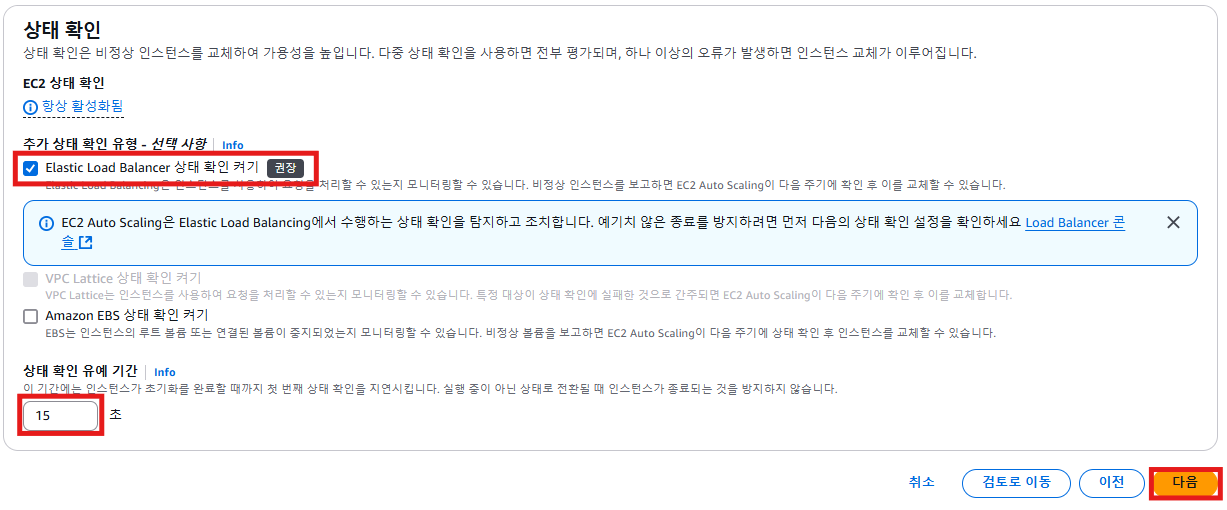
- Elastic Load Balancer 상태 확인 켜기
- 트래픽이 인가가 잘 안되는 상태 ➡️ Auto Sacling에 전달되는 트래픽 인가 차단
- 상태 확인 유예 기간 : 부팅되는 시간
- Auto Scaling을 통해 생성되는 인스턴스도 Target Group에 포함이 되어 health check를 하게 되는데, 이때 인스턴스가 생성된 후에 health check하라는 뜻
- Elastic Load Balancer 상태 확인 켜기
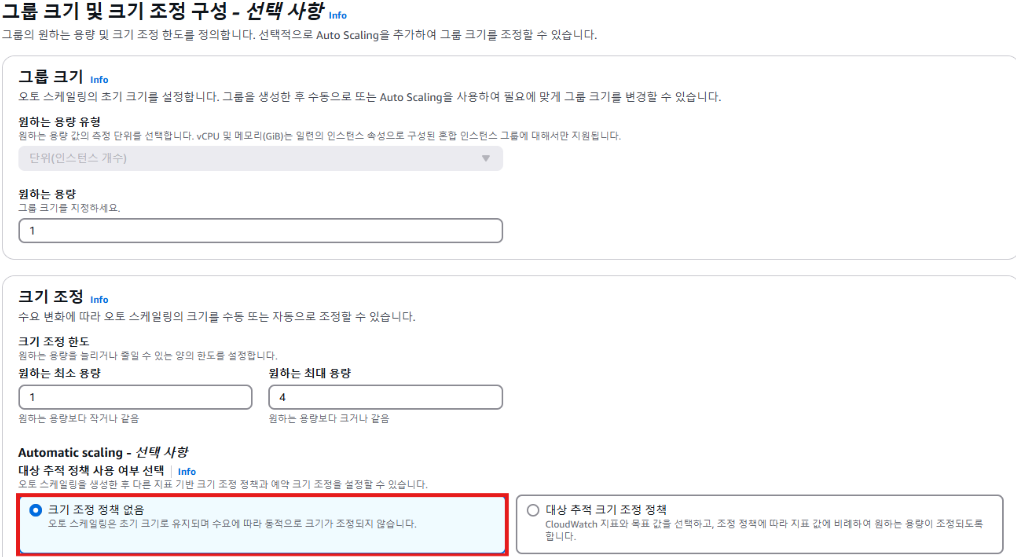
- 그룹 및 크기 조정 구성
- 원하는 용량 = 바램
- 원하는 용량과 현재 상태는 다름 ➡️ 단, 원하는 용량에 수렴하도록 시도할 것
- 크기 조정
- 원하는 최소 용량 = 최소 줄어들 수 있는 인스턴스의 Limit
➡️ CPU 사용량이 부족해도 서버가 최소 1대 이상 - 원하는 최대 용량 = 최대 생성될 수 있는 인스턴스의 Limit
➡️ 아무리 CPU 사용량이 많아도 최대 서버는 4대
- 원하는 최소 용량 = 최소 줄어들 수 있는 인스턴스의 Limit
- 원하는 용량 = 바램
- Auto Scaling Group을 생성할 때, 크기조절 정책을 만들면 때에 따라서 생성 ⭕/❌
➡️따로 생성할 예정
💡참고 : Auto Scaling Group에서 생성하는 방법
사용량을 확인하기 위해 모니터링 필요
- 생성 확인
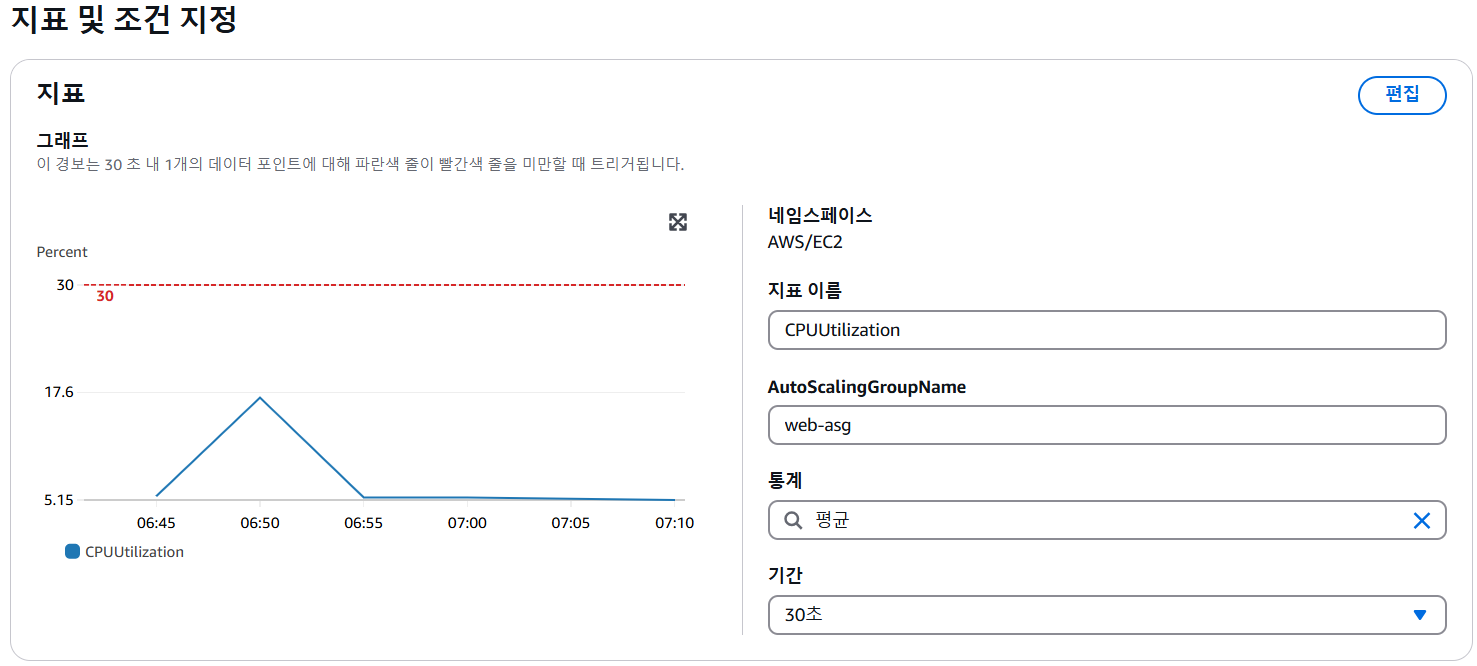
5. Cloud Watch 지표 확인 & 생성(scale-out)
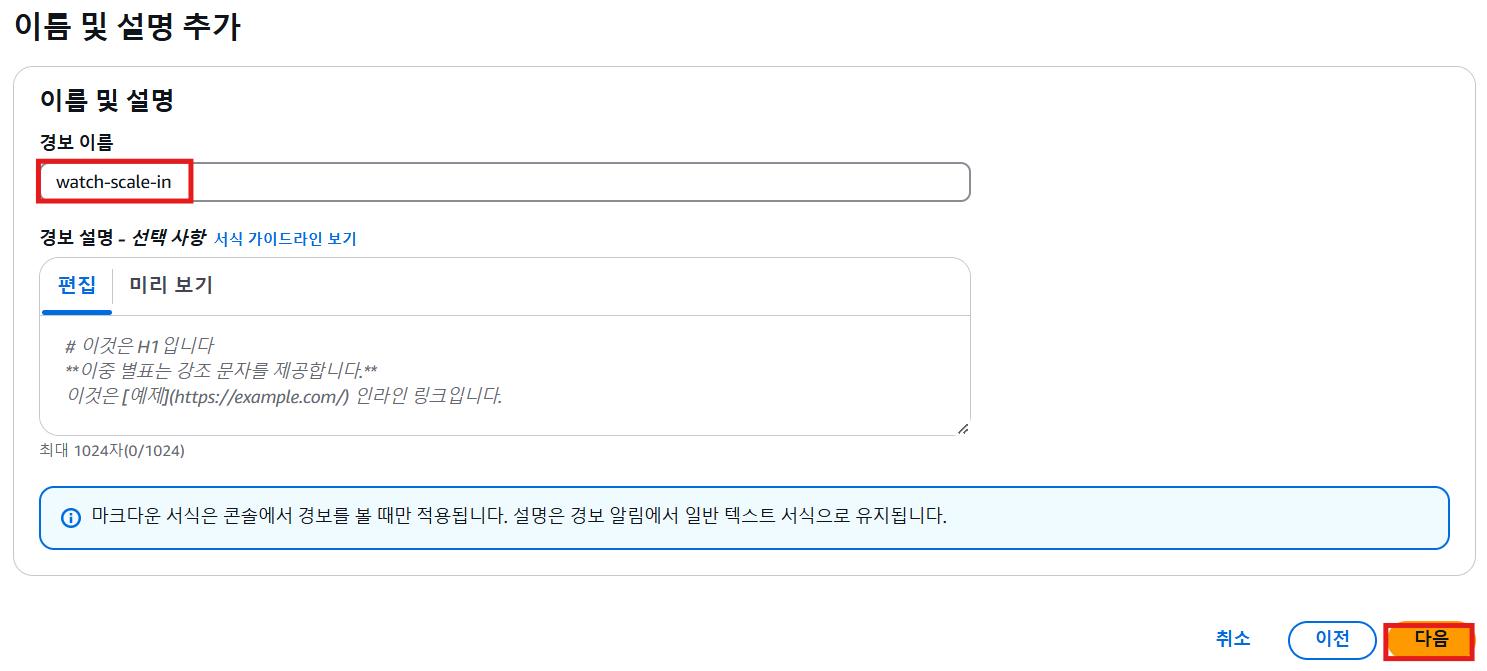
- 경보 생성
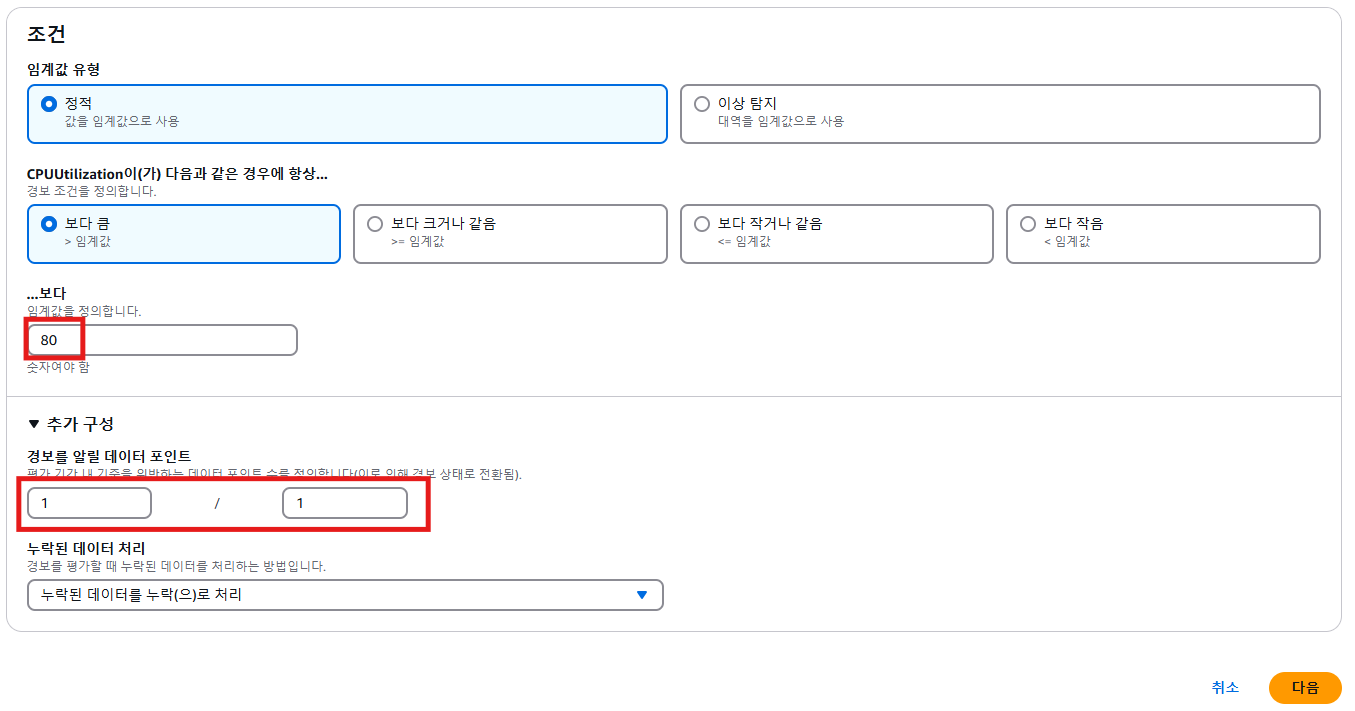
- 경보를 알릴 데이터 포인트
- 모니터링 1회시, CPU 사용량이 80%이상 트리거
- 알림 제거
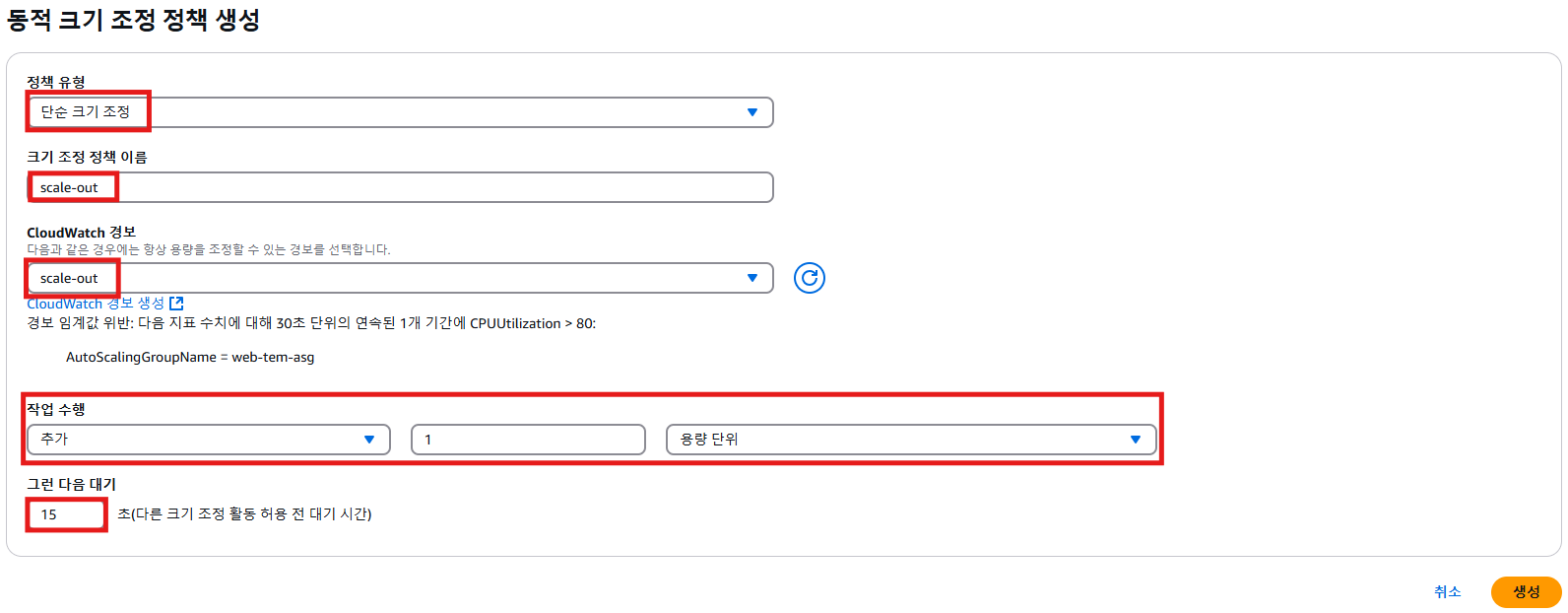
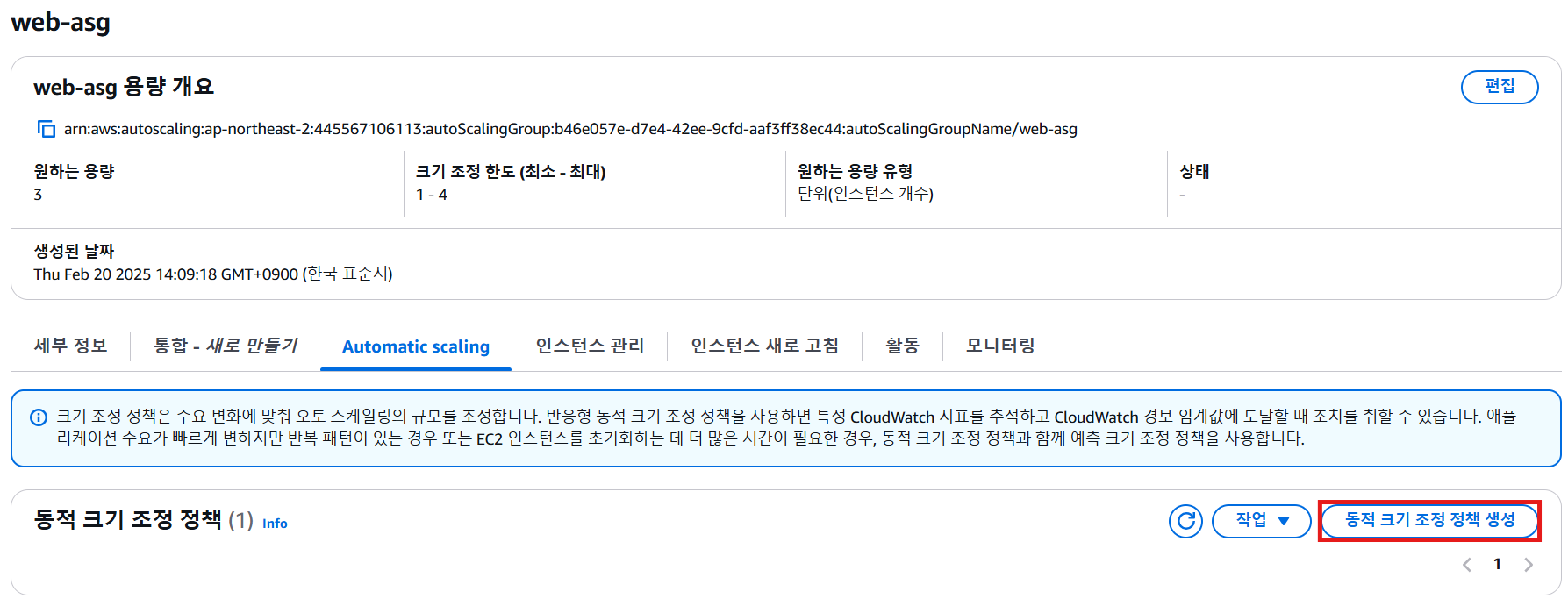
6. 동적 크기 조정 정책 생성
- 정책과 경보가 매칭되어야 함
- 작업 수행
- 경보가 발생하면 1대가 생성되고 15초 정도 대기 후, 경보가 발생하면 인스턴스 생성됨
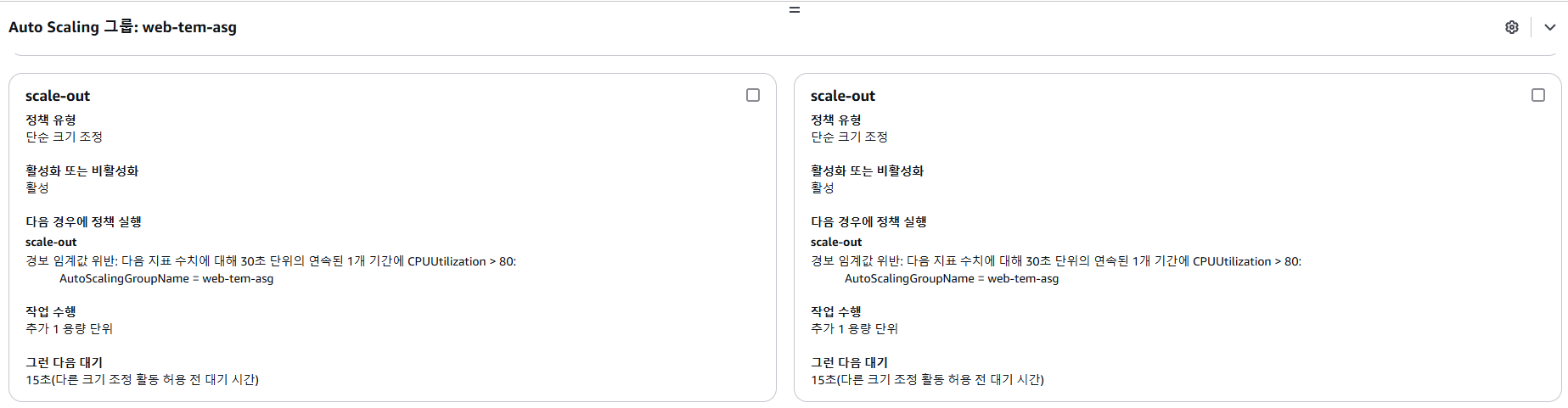
- 동적 크기 정책 확인
7. 부하 테스트
- 부하를 주기 위해 서버 접속
- public IP 복사
7-1. 인스턴스의 Public IP로 SSH 접속
- 서버에 부하를 줘서 Auto Scaling에서 인스턴스가 생성되는 것을 확인
- 인스턴스가 늘어나는 것은 5~10분 정도가 소요됨
7-2. EC2 인스턴스 연결
- 부하 발생 & CPU 점유율 확인
7-3. 부하에 따라 인스턴스가 생성되는 것을 확인
Scale In 정책
더보기





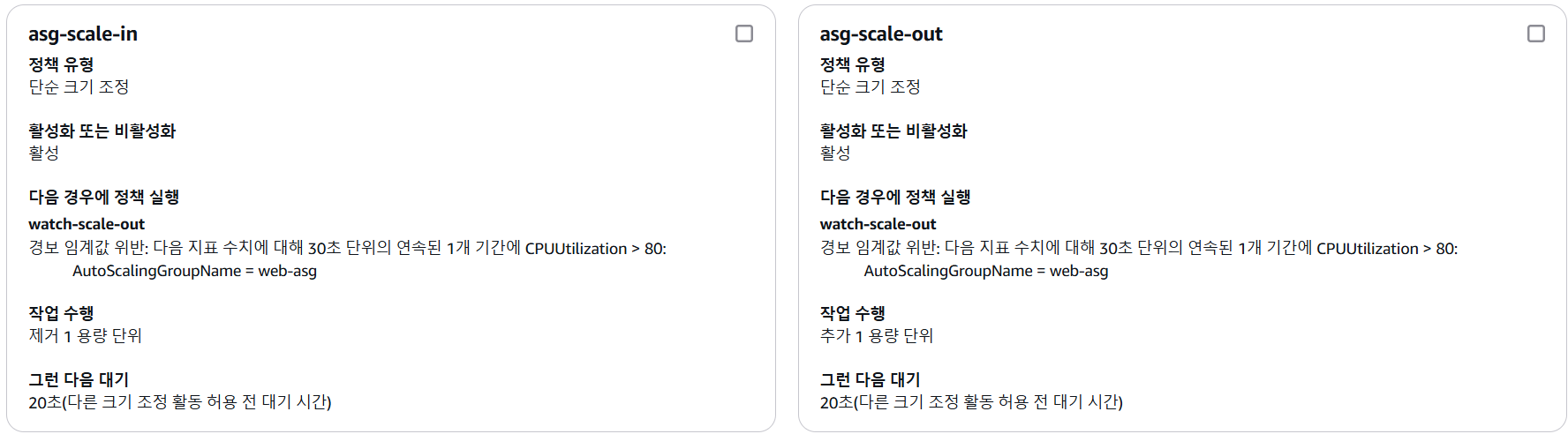
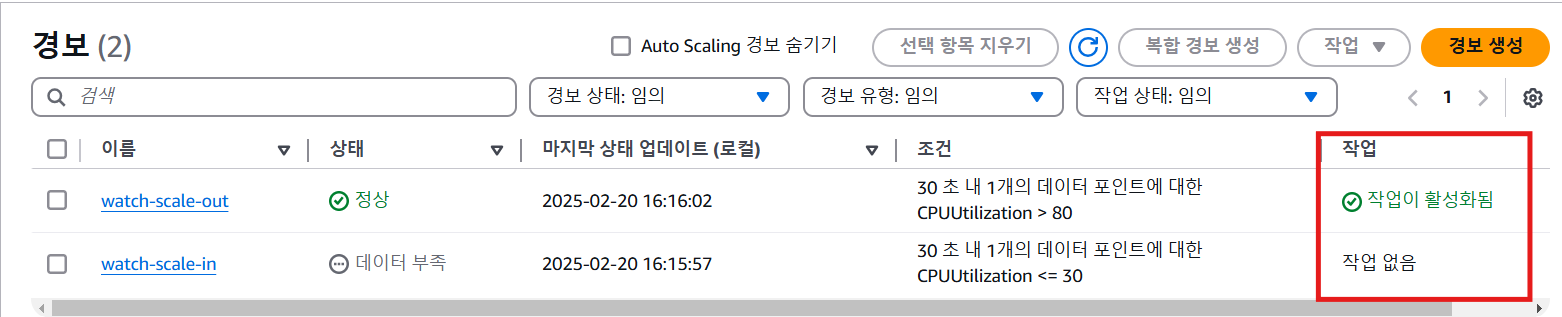

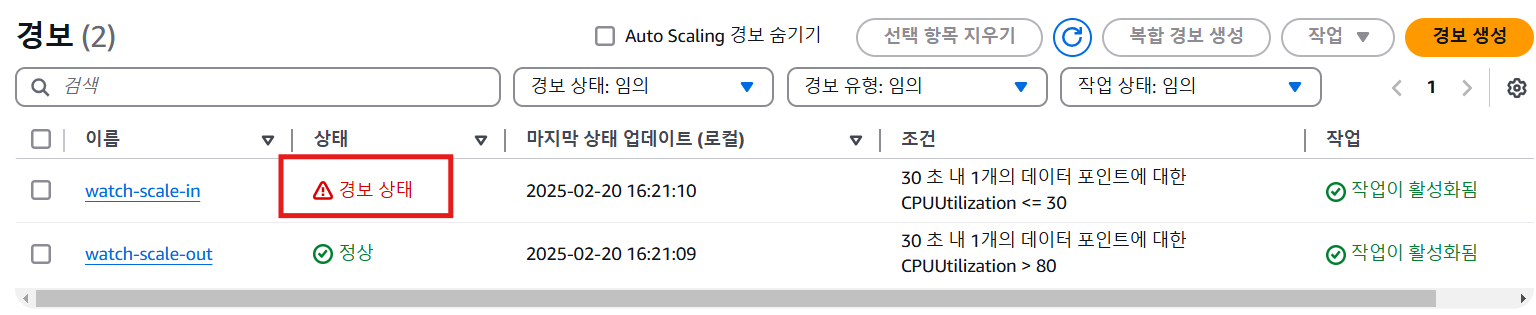
cloud watch 경보 확인
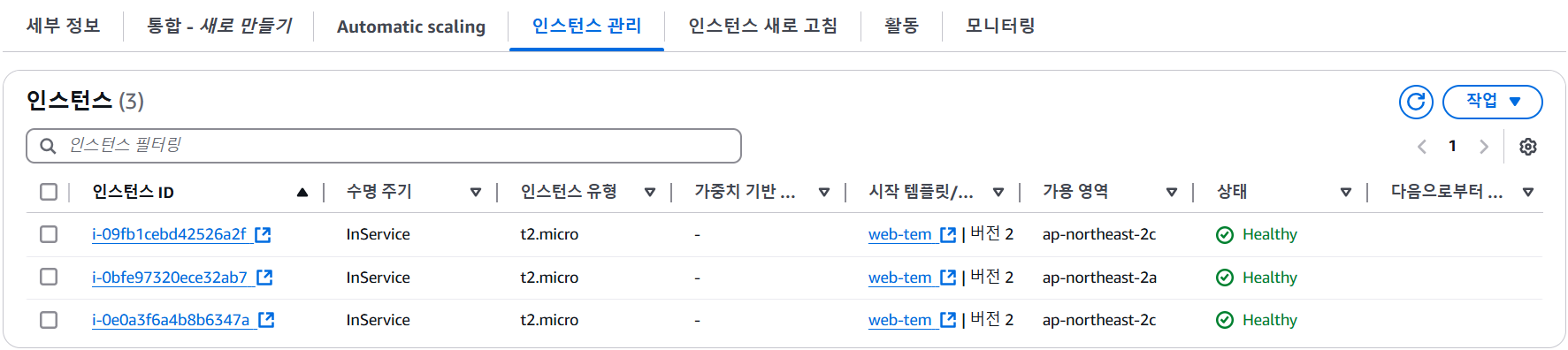

인스턴스 변화 확인
1. 동적 크기 조정 정책 생성 - Scale In
2. Cloud Watch 경보 생성
- 크기 조정 정책 생성 확인
➕ 경보 - Auto Scaling 연결 확인 방법
3. 동적 크기 조정 정책 생성
4. Cloud Watch의 경보 & Scale in 정책 적용 확인
'CS > AWS' 카테고리의 다른 글
| [AWS] 05-1. Router53 & S3 & TLS(HTTPS) & Cloudfront (0) | 2025.02.21 |
|---|---|
| [AWS] 04-2. 시작 템플릿 & Auto Scaling 실습 (0) | 2025.02.20 |
| [AWS] 03-2. AWS ELB 실습(ALB & AMI) (2) | 2025.02.19 |
| [AWS] 03-1. Custom AMI & ELB(ALB, NLB) (0) | 2025.02.19 |
| [AWS] 01. AWS & VPC(Virtual Private Cloud) (1) | 2025.02.18 |
'CS/AWS' Related Articles
more



